? 10 min
Bias = predrasude u korist ili protiv određene stvari, osobe ili grupe, u usporedbi s drugom, obično na način koji se smatra nepravednim.
U današnje doba, oslanjamo se na računala za razne odluke: računala većinom mogu odlučivati brže i bolje nego ljudi. Bilo da provučeš karticu u trgovini, otvoriš Netflix da baciš oko na njegove preporuke ili pretražiš svoje računalo za onu jednu datoteku koju baš ne možeš naći, računalo uzima u obzir podatke koji su mu dostupni, pokreće algoritam i daje ti rezultat. Ti podaci mogu biti tvoje stanje računa, povijest gledanja sadržaja ili indeks tvojih datoteka, ali mogu biti i nešto puno bitnije, a dok počinjemo vjerovati računalima da obavljaju sve više zadataka koje su prije radili ljudi, kako se možemo uvjeriti da uistinu donose ispravne odluke? Donose li ih uopće sada? Ili računala zapravo pojačavaju seksizam i rasizam?
Za bolje razumijevanje ovih pitanja, evo kratkog uvoda u načine razmišljanja računala. Ako već imaš znanja o algoritmima i strojnom učenju, slobodno preskoči na iduću sekciju.
Tradicionalni algoritmi vs. strojno učenje
Računala nisu baš prepametni strojevi sama po sebi. Na niskoj, procesorskoj razini, mogu izvršavati samo prilično jednostavne instrukcije, što su većinom razni jednostavni izračuni (poput zbrajanja dva broja ili vraćanja vrijednosti sinusa) ili upute pohrane – poput “stavi ovaj broj na ovo mjesto u memoriji”). Kao što svatko tko je slušao Arhitekturu računala na faksu zna, ovo je činilo pisanje programa za njih jako, jako napornima. Stoga, izumili smo programske jezike da nam olakšaju stvari. Ipak, programski jezici – iako su nam pružili “logiku više razine” kao alat, olakšavajući pisanje programa – nisu promijenili prirodu programiranja toliko: još uvijek smo zadavali računalima niz uputa koje bi izvršavala na skupu zadanih podataka – algoritam.
Kako su računala napredovala, u tradicionalnom ljudskom duhu, očekivali smo više od njih. No, neki od problema koji su bili stvarno jednostavni nama – poput prepoznavanja predmeta na slici, vožnje automobila ili razumijevanja ljudskog jezika – činili su se jako teški za riješiti. Onako, jako teški. Onako, skoro nemogući za točno riješiti u programskim jezicima koje smo imali, teški.
Da bismo riješili ove probleme, uzeli smo ideju iz znanstvene fantastike i okrenuli smo se umjetnoj inteligenciji, razmišljajući o načinima da naučimo strojeve kako učiti, umjesto da ih učimo određenom zadatku. Znam da to zvuči abstraktno, ali razmišljajte o tome kao razlici između dati nekome ribu i naučiti ga pecati.
Jedan od značajnijih dijelova umjetne inteligencije je strojno učenje, koje Wikipedia definira kao “proučavanje algoritama koji se automatski poboljšavaju kroz iskustvo”. Iako je to ogromno polje s višestrukim pristupima izgradnji takvih algoritama, u osnovi, koristi posebne algoritme (algoritme strojnog učenja) koji grade matematičke modele oko primjera podataka (podataka za učenje). Nećemo ulaziti duboko u strojno učenje, ali ovo znači da nemamo puno utjecaja na to kako ovi algoritmi rade, osim rada na algoritmima koji generiraju modele i na podacima za učenje.
Kako onda uopće znamo da postoji bias u algoritmima i kako ga možemo popraviti?
Problemi s otkrivanjem biasa u algoritmima
Naravno, kad pogledamo kod tradicionalnog računalnog programa, uglavnom možemo vidjeti bias:
if (macka.imaDlaku == false) macka.cijena = macka.cijena * 20;
Ovi biasi mogu se uloviti samim promatranjem koda i uglavnom su predvidljiva (iako priklonjenom) ponašanju, stoga je očito lagano naći bias u kodu kojeg pišu ljudi.
S druge strane, kod kojeg pišu računala – poput algoritama nastalih strojnim učenjem – nisu toliko čitljivi ljudima: poput nekakve crne kutije su. Sad nam se nameće zadatak određivanja ima li algoritam kojeg ne možemo skroz razumjeti bias.
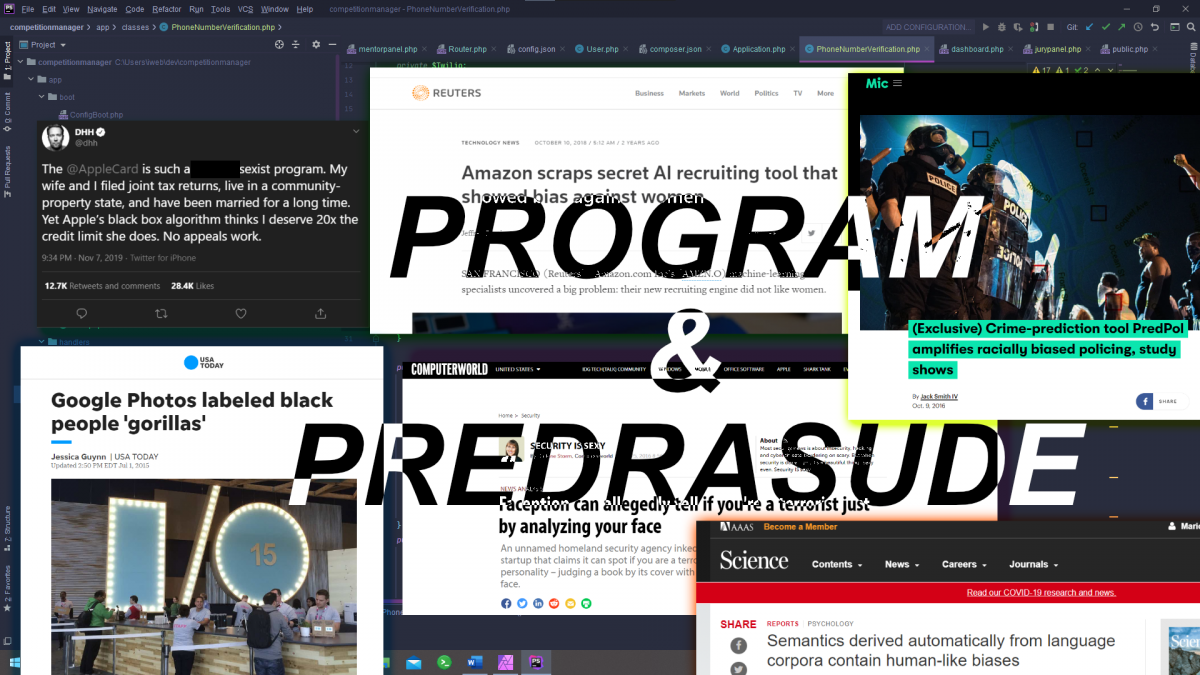
U nekim slučajevima, bias se čini očitim, ali nije jednostavan za dokazati: Apple Card algoritmi davali su niže limite ženama (što je David Heinemeier Hansson vulgarno opisao u svom popularnom tweetu prošle godine). Ipak, kako podaci za učenje nisu uključivali spol kao varijablu i kako su Apple i Goldman Sachs (partnerska banka za Apple Card) pokušali objasniti situaciju, čini se da situacija nije baš crno-bijela, te ne postoji jasan (ili barem javan) konsenzus ima li (tj. je li imao) algoritam bias. (Zadržat ću svoje misli za sebe, jer ne želim baš naljutiti nijednu stranu ovdje, ali ima mnogo više toga u igri oko spolnog biasa osim pukog gledanja spola, budući da postoji mnogo varijabli koji mogu korelirati sa spolom osobe, poput trgovina u kojima kupuju, što je sigurno faktor u bilo kojem algoritmu za kreditni rejting, a postoji značajna šansa da su neke od ovih varijabli utjecali na sklonost odluka algoritma).
U drugim slučajevima, skroz su očiti: Amazonov algoritam za zapošljavanje diskriminirao je žene kažnjavajući korištenje riječi “žena”, što je u konačnici dovelo do propasti projekta nakon izazova da ga učine pravednim i korisnim, osobito u isto vrijeme: posljednja iteracija je bila manje diskriminirajuća, ali je davala gotovo nasumične odluke. Googleova aplikacija Fotografije označavala je slike crnaca kao gorile, rezultirajući time da je Google blokirao u potpunosti oznaku ‘gorila’ dok nisu imali dovoljno vremena da poprave problem.
Tvrtke tvrde da njihovi algoritmi mogu reći jesi li terorist, akademski istraživač ili ekstrovert samo iz slike tvoga lica. Istraživači tvrde da mogu pogoditi tvoju seksualnu orijentaciju iz osobina tvoga lica. Naoko, njihovi algoritmi imaju solidnu točnost – negdje oko 80 do 90 posto. Kako? Nije li ovo samo fiziognomija na steroidima?
Fiziognomija je praksa procjenjivanja karaktera osobe ili njihove osobnosti iz njihovog vanjskog izgleda – pogotovo lica.
Wikipedia
Odakle uopće bias?
Da bismo razumjeli kako možemo prepoznati bias, moramo saznati kako algoritam uopće počne imati predrasude.
Postoje tri osnovne vrste algoritamskog biasa: već postojeći, tehnički i nastali.
Tehnički bias se uglavnom najlakše nađe i popravi: nastaju zbog ograničenja algoritama, njegovih mogućnosti računa ili drugih ograničenja sustava. Primjerice, algoritam koji sortira imena kandidata abecednim redom ima bias u korist onih kojima imena počinju na A. Turnitin, alat za detekciju plagijarizma imao je bias u korist nativnih govornika engleskog jezika budući da su bili bolji u promjeni riječi i strukturi kod kopiranja, manje aktivirajući detektor plagijarizma nego ne-nativni govornici u slučajima kad su obje grupe plagirale.
Postojeći bias nastaje kad se algoritmi razvijaju koristeći pretpostavke koje imaju predrasude ili uče na podacima koji imaju bias: kodirajući ljudske predrasude u algoritme. Društvene i institucionalne predrasude prelijevaju se u kod, potencijalno utječući na odluke algoritma u budućnosti, pogotovo ako uzima u obzir svoje prethodne odluke.
Nastali biasi događaju se kad se algoritmi ne mijenjaju, ali se kontekst mijenja. Algoritmi nisu adaptirani na nove oblike znanja, ali možda su se kulturne norme promijenile. Možda su podaci na kojima su učeni razlikovali značajno od stvarnih podataka koje moraju evaluirati. Možda su zapeli u petlji povratnih informacija, što se može dogoditi algoritmima za predikitvnu policiju, povećavajući rasne razlike koje su trebali smanjiti. Kad su znanstvenici napravili algoritam koji uči asocijacije riječi s Interneta, usput je naučio predrasude.
Detekcija, prevencija i popravljanje biasa
Kao što smo vidjeli u ovom članku, nismo baš dobri u određivanju ima li algoritam bias uistinu. Nekad je lagan za uočiti, ali težak za popraviti, kako je bilo u slučaju Google Fotografija. Isto tako, nekad je težak za uopće shvatiti, kao što je u slučaju “pogađanja jesi li terorist” zbog kojeg se zapitaš “koji…”
U radu Brookings Institutiona baziranog na uviđavnjima 40 stručnjaka (koji se zovu “vođama misli” u radu, u fraziranju koje podsjeća na 1984.), istraživači predlažu brojne načine suzbijanja biasa u algoritmima, ali bez jasnog odgovora kako istraživači mogu detektirati i prevenirati bias lagano. To je razumljivo: izrada poštenih algoritama zahtjevan je zadatak.
Naravno, trebali bismo dati sve od sebe da popravimo ove probleme, gradeći algoritme kojima možemo vjerovati da će donositi dobre odluke. To je nešto na čemu razvijatelji i operatori algoritama moraju raditi cijelo vrijeme, ne samo u nekom trenutku.
Izgradnja poštenih algoritama započinje ispitivanjem biasa u podacima za učenje, brinući se za raznovrsnost istih i nepostojanje povijesnog ljudskog biasa. Osjetljivim podacima, poput spola, rase, seksualne orijentacije i sl., a koji su prisutni u podacima za učenje bi se trebalo također rukovati pažljivo.
No, ovo može biti zahtjevno: zasljepljivanje algoritma na određenu varijablu može biti nedovoljno: spol se može zaključiti iz tvoga imena, recimo. U većim gradovima, stanovnici nekih kvartova su većinom određene rase, što može učiniti kvart u kojem živiš dobrim prediktorom tvoje rase. Zasljepljivanje također može uvesti dodatan bias u algoritam, forsirajući ga da ignorira zbilja relevantne, ali osjetljive varijable. Ovo čini izradu algoritama koji su pošteni prema tradicionalno marginaliziranim skupinama puno kompliciranijom, ali je neizbježan korak u dizajnu algoritama. Raznolikosti u timu razvijatelja naizgled pomažu u ovom zadatku.
Osiguravanje poštenja nastavlja se i nakon učenja algoritma. Razvijatelji bi trebali ispitati rezultate za anomalije: primjerice, uspoređujući ishode između različitih skupina, što se može učiniti i u simulacijama. Ovo nastavlja biti zadatkom čak i kad se algoritam pusti u produkciju i počne koristiti u stvarnom svijetu.
Ipak, novo pitanje se javlja s ovim pristupom: jesu li nejednaki ishodi nepošteni? Jasno, Jeff Bezos ima bolji kreditni rejting od mene: ovo je nejednak ishod, ali nije zbilja nepošten.
Čini se da neki kompromisi između poštenja i točnosti su inherentni u svakom odlučivanju, algoritamskom ili ne. Kako onda postavljamo standarde oko toga kakva je diskriminacija okej?
U slučaju ljudskih predrasuda, obično se reguliraju kroz zakone koji zabranjuju korištenje određenih podataka u donošenju odluka, ali vidjeli smo kako ovo može postati teško: algoritmi mogu diskriminirati puno suptilnije i vrlo različito od ljudi. Predlagatelji politike umjetne inteligencije predlažu stvaranje etičkih okvira oko algoritamskog donošenja odluka koji bi pokušali osigurati da algoritmi izbjegavaju “nepravednu diskriminaciju”.
Europska unija već je stvorila jedan takav okvir, pod imenom Etičke smjernice za umjetnu inteligenciju kojoj se može vjerovati, koja traži da umjetna inteligencija ima ljudsko upravljanje i nadzor, tehničku robustnost i sigurnost, upravljanje podacima i privatnošću, transparentnost, raznolikost, nediskriminaciju i poštenje, društvenu i okolišnu dobrobit i odgovornost usađene kako bi se smatrala vrijednom povjerenja od strane EU.
Ovo se čini odličnim početkom, ali ostavlja nas s jednim velikim pitanjem: kako mjerimo poštenje? Ne postoji intuitivan odgovor ili čak trag konsenzusa oko ove teme. Neki istraživači predlažu pitanje “Hoćemo li staviti određene grupe ljudi u goru poziciju kao posljedicu dizajna algoritma ili neželjenih posljedica algoritma?”. Druge preporuke uključuju izjave o utjecanju na bias, što su zapravo upitnici dizajnirani da navode razvijatelje algoritama kroz dizajn, implementaciju i nadzor svojih algoritama.
Na kraju, ova rasprava nas ostavlja s više pitanja nego što daje odgovora. Svakako, moramo ispravno dizajnirati podatke za učenje i analizirati algoritme, ali bez dodatnog ljudskog upliva (pogotovo od strane ljudi koji su naučeni prepoznati svoj bias), samoregulacije razvijatelje, javne politike i pogotovo transparetnosti, naši će algoritmi biti u najmanju ruku jednako puni predrasuda kao i mi sami.
Reference i dodatno čitanje:
https://www.wired.com/story/the-apple-card-didnt-see-genderand-thats-the-problem/
https://en.wikipedia.org/wiki/Algorithmic_bias
https://www.wired.com/story/the-real-reason-tech-struggles-with-algorithmic-bias/
https://en.wikipedia.org/wiki/Machine_learning
https://en.wikipedia.org/wiki/Artificial_intelligence
https://en.wikipedia.org/wiki/Physiognomy
https://medium.com/@blaisea/physiognomys-new-clothes-f2d4b59fdd6a